Running Dapr in production at Roadwork
At Roadwork our mission statement is “To create a platform that allows our customers to gain actionable insights from their data without additional operational effort”. We work towards optimizing processes and gaining value out of your data.
We can summarize the lifecycle of such a system in the classical data platform approach, where we have three main phases: “Data gathering”, “Data processing” and “Data analytics”. The further you get in this cycle, the more complex operations and knowledge becomes and the more expensive your bill will be.
To accomplish our mission, we had to start – as most startups – by creating a smaller tool that would allow us to get started and bootstrap the company for our ultimate vision of creating an autonomous system. This is why we started Scraper.AI, which implements a part of the first phase for web specific tasks – “Data gathering”. Scraper.AI allows any user to go to any website, point to the data they would like to extract or monitor, it extracts the data and then presents it in a structured way back to the user.
Today, just a couple of months after launching, Scraper.AI has over 4000 users and more than 100 paid customers that are using the service. On a processing level, we have over 5000 website extraction jobs created with 1500 being scheduled on a recurring interval (hourly, daily, weekly and monthly), resulting in the processing of around 3200 websites per day.
Challenges and requirements
Under the hood Scraper.AI creates a web browser instance that executes the actions set by the user. An instance consumes around 2048MB in RAM and has a duration of 30 seconds on average. This creates the problem of how to scale such a system. Furthermore, there are multiple of these running in parallel with a very dynamic workload (scheduled -> 24/7 running & on-demand -> variable workload scaling)
Summarizing these requirements you have the following:
- An on-demand vs scheduled workload
- 2GB RAM, ~30s avg workload execution time
- Hardware & software requiring an automated scaling solution
Looking at one of the first solutions that developers often consider about when reading those, we can instantly think of utilizing “serverless” components such as functions. However, if we calculate this for 1536MB (the cap for Azure Functions) and 500 executions per hour for an entire month (= 366,000 executions) you get a monthly bill of $257.12 (including free executions). We could optimize this, but it is clear that it could become an expensive solution over time as we scale.
Furthermore, we wanted to keep our solution “portable” and “cloud-agnostic” so it can be moved anywhere we want, avoiding vendor “lock-in” as much as possible.
After researching this a while, we found a combination of solutions that could help us.
- Dapr: A portable, event-driven runtime that makes it easy for developers to build resilient, microservice stateless and stateful applications that run on the cloud and edge and embraces the diversity of languages and developer frameworks.
- KEDA: Event-driven autoscaling for Kubernetes
The architectural diagram explain to explain the solution is shown below.
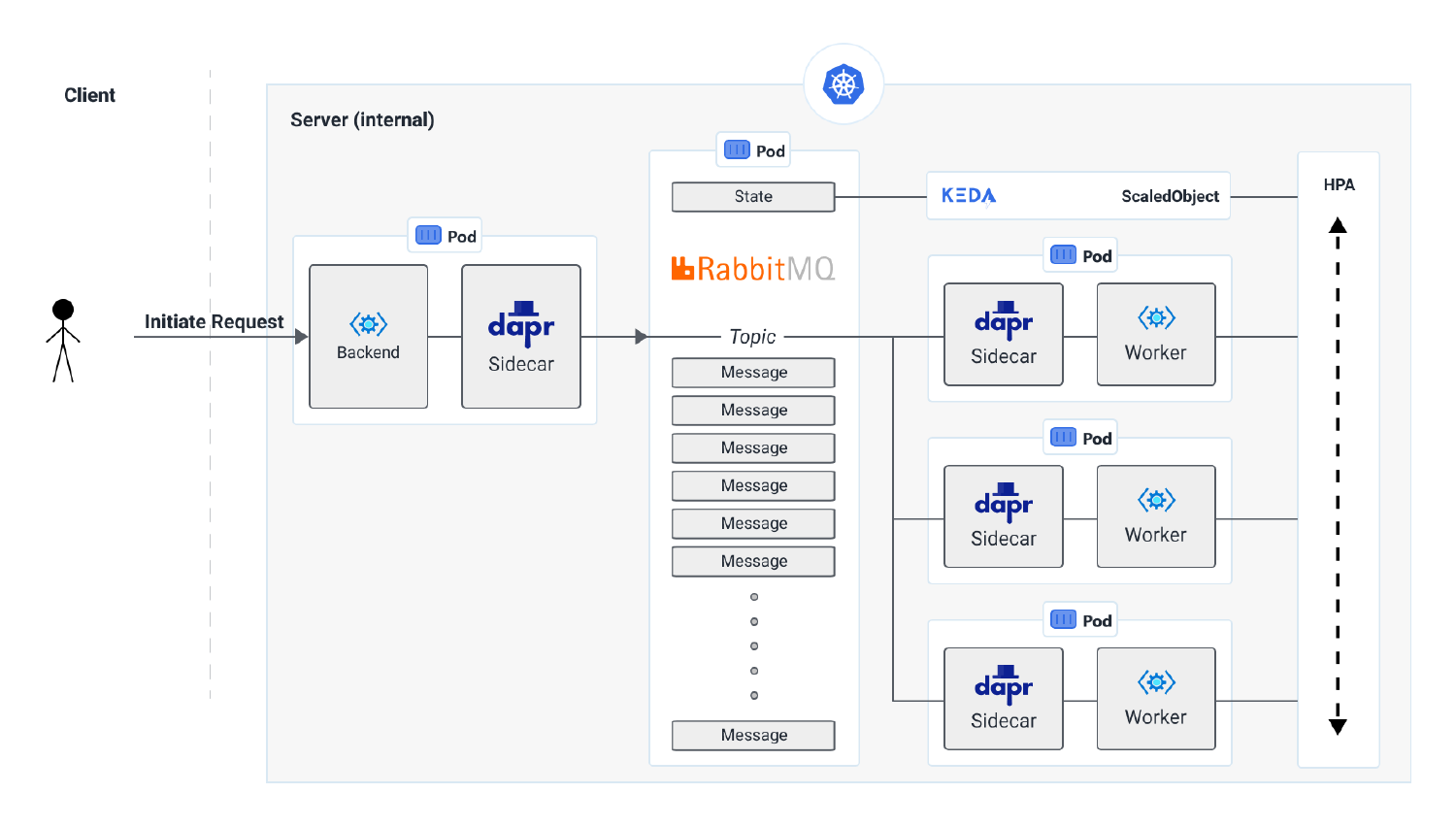
As you can see in the above diagram, a queue is utilized (albeit split up to an on-demand queue and scheduled queue) where work items are coming in. Now, here is where Dapr comes in - we utilize its bindings to connect to RabbitMQ and we only need to call a simple REST interface. On top of this we deployed KEDA on the Kubernetes cluster to monitor the queue size. Once the items in this queue exceed a certain threshold, KEDA scales out the deployment automatically to add extra pods to the cluster.
While the above solution handles autoscaling the workload, we still have to autoscale the Kubernetes cluster. Since we are using a managed Kubernetes cluster (AKS) we utilize the autoscaling capabilities built into the service which resolves the infrastructure scaling issue.
Conclusion
The solution above has now been running in a production environment for the last three months. In the span of these three short months we have also made use of the portability of the solution! We moved the entire solution from Digital Ocean (was missing service accounts, crucial for security purposes) to AWS and finally to Azure with migrations taking only a couple of hours, since all we had to do is just configure Kubernetes, Dapr and KEDA again and we were all set-up and running again!
We’ve learned a ton in the past few months about Dapr! So much that we have even opened a few pull requests and are actively contributing in the – amazing – community.
Next steps
As for our next steps, we have currently finished the first tool in our toolset and are now heavily working towards our autonomous agent! Luckily, we have Dapr there to help us again make this project become a reality 😉